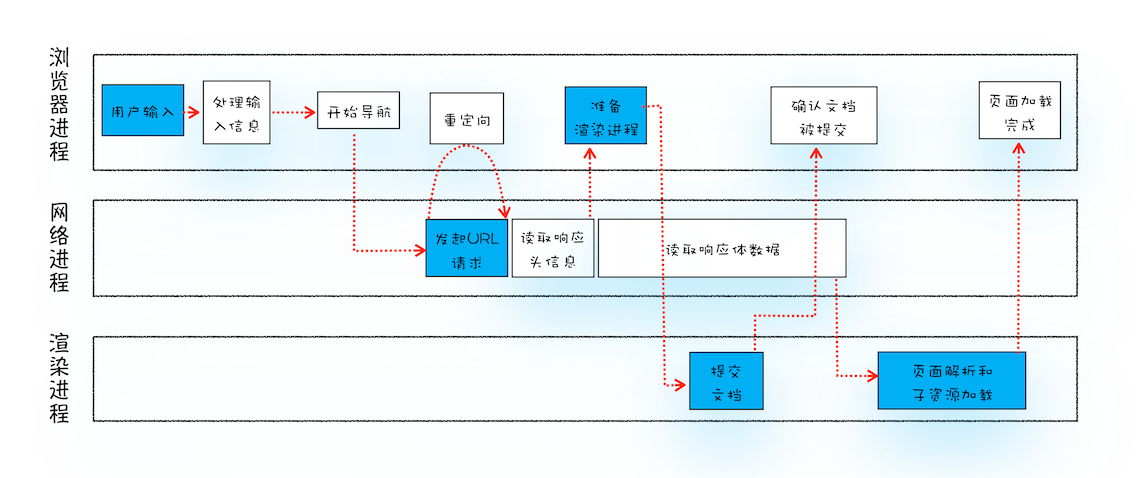
- 用户输入关键字并键入回车
- 当前页面可以触发触发 beforeunload 事件,比如表单未提交完成,来防止用户未保存就离开
- 浏览器进程解析 URL:
- URL 中的协议或者主机名不合法,将会把地址栏中输入的内容传递给搜索引擎
- 浏览器会检查 URL 中是否出现了非法字符,如果存在非法字符,则对非法字符进行转义后再进行下一过程
- 浏览器进程通过进程间通信将该 URL 转发给网络进程;
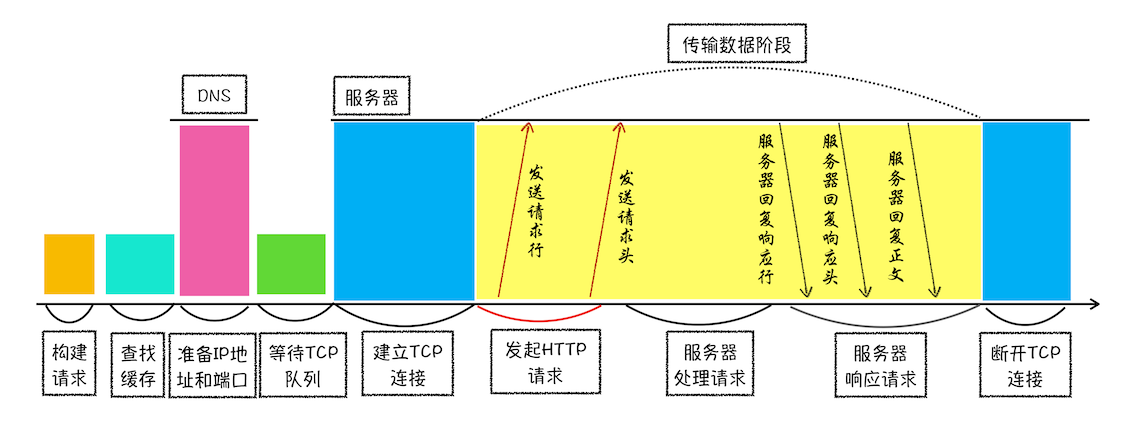
- 缓存判断:网络进程会判断所请求的资源是否在缓存里,如果请求的资源在缓存里并且没有失效,那么就直接使用,否则向服务器发起新的请求。良好的缓存可以有效优化 TTFB 指标,
- 网络进程发起真正的 URL 请求
- 网络进程接收到了响应头数据,解析响应头数据,并将数据转发给浏览器进程;
- 重定向:返回的状态码是 301 或者 302,网络进程会从响应头的 Location 字段读取重定向地址重新发起请求
- 响应数据类型:返回的状态码是 200,则从响应头的 Content-Type 判断返回体的响应数据类型。
- 在这个过程,我们可以通过降低资源体积来进行请求加速,比如 webpack 的
tree-shaking、Code Splitting 等,现代框架本身已经帮我们实现并做好了,我们更多需要良好的开发习惯,如 TDD 保证代码可读和稳定性,避免由于不敢改代码带来大量重复实现,最终导致构建产物过高。
- 浏览器进程接收到网络进程的响应头数据后,发送“提交文档”的消息到渲染进程;
- 渲染进程接收到“提交文档”消息后,便开始准备接收 HTML 数据,接收数据的方式是直接和网络进程建立数据管道;
- 但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。官方把这个默认策略叫 process-per-site-instance。这就导致,我们有时多开了几个 tab,却使整个浏览器卡死
- 等文档数据传输完成后,渲染进程会返回“确认提交”的消息给浏览器进程
- 浏览器进程接收到渲染进程“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 界面。
- 渲染进程开始页面解析和子资源加载,接收到多少,渲染多少,而且在整个过程中,我们无需考虑 CSS、JavaScript 来自哪里,关联的页面是否来自同一个网站。从系统集成的角度,CSS、JavaScript 或者页面中通过超链接引用的其他页面,都可以看作是对当前页面的增强,比如我们为了让网页在移动端访问时获取定位能力,则可以引入通过设备信息判断是否时移动端,来引入地图相关的 js 文件。这种分布式超媒体是互联网的集成策略,也是 Restful 的设计理念来源。
- 客户端确认数据发送完成,进行 TCP 四次挥手断开连接,HTTP 1.1 的引入了 Keep-alive,可以让 TCP 连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个 TCP 连接发送请求。保持 TCP 连接可以省去下次请求时需要建立连接的时间,提升资源请求速度。