- 客户端-服务端(Client-Server): 这个更专注客户端和服务端的分离,服务端独立可更好服务于前端、安卓、IOS等客户端设备。
- 无状态(Stateless):服务端不保存客户端状态,客户端保存状态信息每次请求携带状态信息。比如 Cookie 等
- 可缓存性(Cacheability) :服务端需回复是否可以缓存以让客户端甄别是否缓存提高效率。
- 统一接口(Uniform Interface):通过一定原则设计接口降低耦合,简化系统架构,这是RESTful设计的基本出发点。当然这个内容除了上述特点提到部分具体内容比较多详细了解可以参考这篇REST论文内容。
- 分层系统(Layered System):客户端无法直接知道连接的到终端还是中间设备,分层允许你灵活的部署服务端项目。
- 按需代码(Code-On-Demand,可选):按需代码允许我们灵活的发送一些看似特殊的代码给客户端例如JavaScript代码。
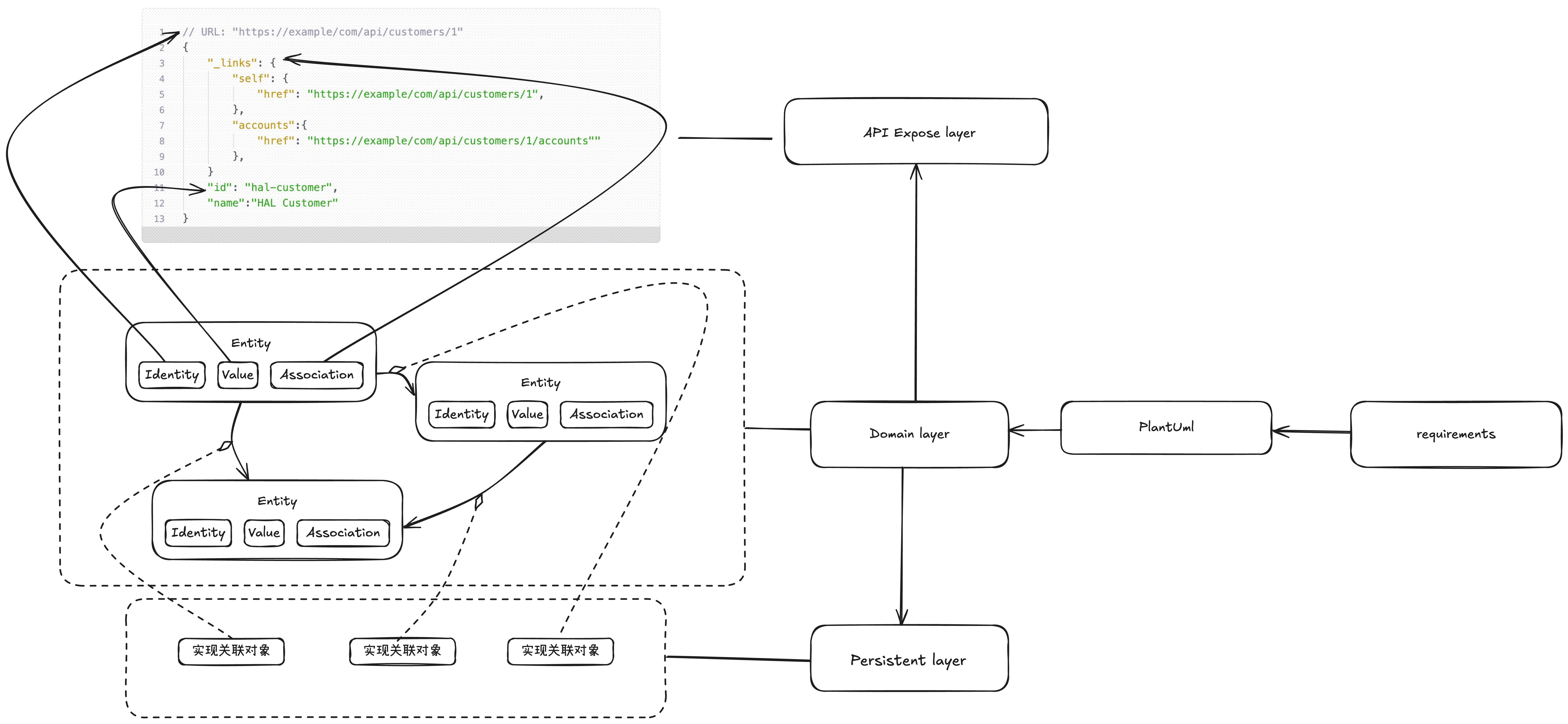
传统的 JDBC 形式,需要大量散落在各处的 service 和 mapper 来保持生命周期一致性,每次我们新增一个功能,都需要在整个项目中,调用大量之间没什么关联的 service,形成一个巨大的 service 调用网络。
很多人使用 JDBC 的形式去使用 DDD,最终却发现,越是复杂的项目,service 调用网越混乱,新增功能时越是难以找到需要用的 service。最终只能得出一个 DDD 无用的结论。
还有一个现象是,很多人用 AI 会在 prompt 中,要求 AI 遵循 SOLID 原则,最终导致项目中有大量的只有一两个方法的 service。虽然遵循 SOLID,但是却无法从代码中,反推出背后有哪些业务在调用它。
而 sub-resource 的形式,更适合 DDD 映射业务模型的关联关系,下面是 java 的 spring hateaos 下的形式,ts 目前没有相关的框架,也许可以这么设计 restful web service spike
// 根入口 customer
@Path("/customers")
public class CustomersApi {
private Customers customers;
@Inject
public CustomersApi(Customers customers) {
this.customers = customers;
}
@Path("{id}")
public CustomerApi findById(@PathParam("id") String id) {
return customers.findById(id).map(CustomerApi::new).orElse(null);
}
}
public class CustomerApi {
private Customer customer;
public CustomerApi(Customer customer) {
this.customer = customer;
}
// 获取单个 customer
@GET
public CustomerModel get(@Context UriInfo info) {
return new CustomerModel(customer, info);
}
// 获取 customer 下的 accounts
@Path("accounts")
public AccountsApi accounts() {
return new AccountsApi(customer);
}
}